常用报名考试网基本信息字段设置
第一步:基本信息表单

第二步:附件上传表单

第三步:信息确认表单

mysql一个表中某个字段的值里面的部分字符串,使用mysql replace函数:UPDATE prezzie_category SET image = REPLACE (image, 'http://localhost:8727','https://a.liziyu.com') where id > 0;
注意,操作之前请先备份表:
CREATE TABLE prezzie_category_bak AS SELECT * FROM prezzie_category;
—
coloruiBeta (uni-app版)
github:https://github.com/Color-UI/coloruiBeta
gitee:https://gitee.com/color-ui/coloruiBeta
演示效果:https://cu-h5.vercel.app/
—
MP-CU(微信小程序原生版)
github:https://github.com/Color-UI/MP-CU
gitee:https://gitee.com/color-ui/MP-CU
文档地址:https://mp-cu-doc-vercel.vercel.app/
—
静态资源包
github:https://github.com/Color-UI/assest
gitee:https://gitee.com/color-ui/assest
在线引用:https://colorui-assest.vercel.app/ + 资源路径


登录邮箱下载:Gworg证书文件目录 ,都会有以下五个文件夹。
文件说明
1_root_bundle.crt 证书链文件(*chain.crt)
2_star_gworg_com.crt 公钥文件(*.crt)
3_star_gworg_com.key 私钥文件(*key)

测试学习:可以直接点击:生成开发者测试证书
注:由于证书是未认证的证书,所以不受浏览器信任,会显示为不安全的证书,我们可以通过设置信任证书或者直接点击高级,继续前往就能使用)
(完)
本文转自:
https://www.gworg.com/ssl/1157.html
https://www.gworg.com/ssl/71.html
2022-12-31,
2023-01-01,
2023-01-02,
2023-01-21,
2023-01-22,
2023-01-23,
2023-01-24,
2023-01-25,
2023-01-26,
2023-01-27,
2023-04-05,
2023-04-29,
2023-04-30,
2023-05-01,
2023-05-02,
2023-05-03,
2023-06-22,
2023-06-23,
2023-06-24,
2023-09-29,
2023-09-30,
2023-10-01,
2023-10-02,
2023-10-03,
2023-10-04,
2023-10-05,
2023-10-06,
2023-01-28,
2023-01-29,
2023-04-23,
2023-05-06,
2023-06-25,
2023-10-07,
2023-10-08,
//偷懒,从这里获取即可。
https://github.com/zjkal/time-helper/blob/main/src/ChinaHoliday.php
引用自Wiki:
ASN.1 is a standard interface description language for defining data structures that can be serialized and deserialized in a cross-platform way.
也就是说ASN.1是一种用来定义数据结构的接口描述语言,它不是二进制,也不是文件格式,看下面的例子你就会明白了:
FooQuestion ::= SEQUENCE {
trackingNumber INTEGER,
question IA5String
}
这段代码定义了FooQuestion的数据结构,下面是FooQuestion这个数据接口的某个具体的数据:
myQuestion FooQuestion ::= SEQUENCE {
trackingNumber 5,
question "Anybody there?"
}
ASN.1用在很多地方比如下面要讲的X.509和PKCS group of cryptography standards。
引用自Wiki:
ASN.1 is closely associated with a set of encoding rules that specify how to represent a data structure as a series of bytes
意思是ASN.1有一套关联的编码规则,这些编码规则用来规定如何用二进制来表示数据结构,DER是其中一种。
把上面的FooQuestion的例子用DER编码则是(16进制):
30 13 02 01 05 16 0e 41 6e 79 62 6f 64 79 20 74 68 65 72 65 3f
翻译过来就是:
30 — type tag indicating SEQUENCE
13 — length in octets of value that follows
02 — type tag indicating INTEGER
01 — length in octets of value that follows
05 — value (5)
16 — type tag indicating IA5String
(IA5 means the full 7-bit ISO 646 set, including variants,
but is generally US-ASCII)
0e — length in octets of value that follows
41 6e 79 62 6f 64 79 20 74 68 65 72 65 3f — value ("Anybody there?")
看到这里你应该对DER编码格式有一个比较好的认识了。
引用自Wiki:
Privacy-Enhanced Mail (PEM) is a de facto file format for storing and sending cryptographic keys, certificates, and other data, based on a set of 1993 IETF standards defining “privacy-enhanced mail.”
PEM是一个用来存储和发送密码学key、证书和其他数据的文件格式的事实标准。许多使用ASN.1的密码学标准(比如X.509和PKCS)都使用DER编码,而DER编码的内容是二进制的,不适合与邮件传输(早期Email不能发送附件),因此使用PEM把二进制内容转换成ASCII码。文件内容的格式像下面这样:
-----BEGIN label-----
BASE64Encoded
-----END label-----
label用来区分内容到底是什么类型,下面会讲。
和PEM相关的RFC有很多,与本文内容相关的则是RFC7468,这里面规定了很多label,不过要注意不是所有label都会有对应的RFC或Specification,这些label只是一种约定俗成。
PEM实际上就是把DER编码的文件的二进制内容用base64编码一下,然后加上-----BEGIN label-----这样的头和-----END label-----这样的尾,中间则是DER文件的Base64编码。
我们可以通过下面的方法验证这个结论,先生成一个RSA Private Key,编码格式是PEM格式:
openssl genrsa -out key.pem查看一下文件内容,可以看到label是RSA PRIVATE KEY:
----BEGIN RSA PRIVATE KEY-----
BASE64Encoded
-----END RSA PRIVATE KEY-----
然后我们把PEM格式转换成DER格式:
openssl rsa -in key.pem -outform der -out key.der如果你这个时候看一下文件内容会发现都是二进制。然后我们把DER文件的内容Base64一下,会看到内容和PEM文件一样(忽略头尾和换行):
base64 -i key.der -o key.der.base64上面讲到的PEM是对证书、密码学Key文件的一种编码方式,下面举例这些证书、密码学Key文件格式:
引用自Wiki :
In cryptography, X.509 is a standard defining the format of public key certificates. X.509 certificates are used in many Internet protocols, including TLS/SSL, which is the basis for HTTPS, the secure protocol for browsing the web.
X.509是一个Public Key Certificates的格式标准,TLS/SSL使用它,TLS/SSL是HTTPS的基础所以HTTPS也使用它。而所谓Public Key Certificates又被称为Digital Certificate 或 Identity Certificate。
An X.509 certificate contains a public key and an identity (a hostname, or an organization, or an individual), and is either signed by a certificate authority or self-signed.
一个X.509 Certificate包含一个Public Key和一个身份信息,它要么是被CA签发的要么是自签发的。
下面这种张图就是一个X.509 Certificate:
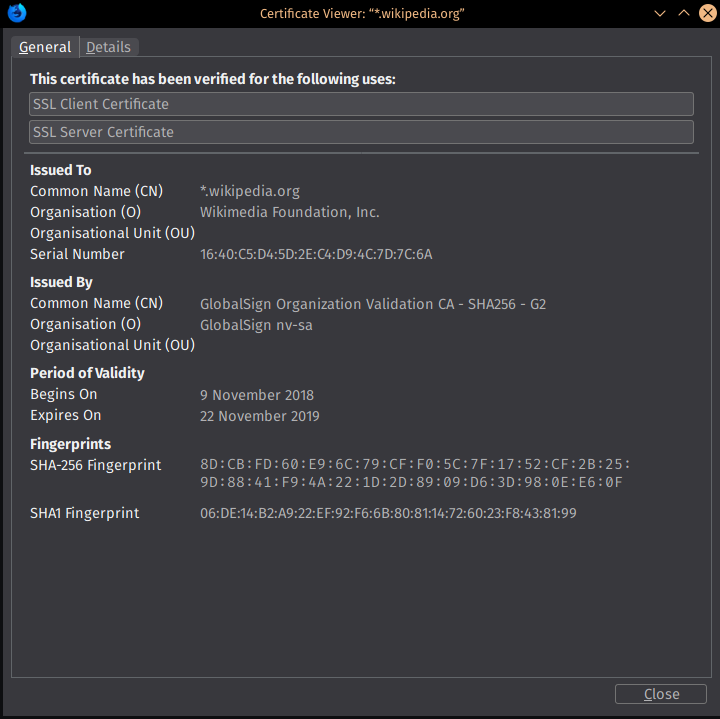
事实上X.509 Certificate这个名词通常指代的是IETF的PKIX Certificate和CRL Profile,见RFC5280。所以当你看到PKIX Certificate字样的时候可以认为就是X.509 Certificate。
引用自Wiki:
In cryptography, PKCS stands for “Public Key Cryptography Standards”
前面提到的X.509是定义Public Key Certificates的格式的标准,看上去和PKCS有点像,但实际上不同,PKCS是Public Key密码学标准。此外Public-Key Cryptography虽然名字看上去只涉及Public Key,实际上也涉及Priviate Key,因此PKCS也涉及Private Key。
PKCS一共有15个标准编号从1到15,这里只挑讲PKCS #1、PKCS #8、PKCS #12。
PKCS #1,RSA Cryptography Standard,定义了RSA Public Key和Private Key数学属性和格式,详见RFC8017。
PKCS #8,Private-Key Information Syntax Standard,用于加密或非加密地存储Private Certificate Keypairs(不限于RSA),详见RFC5858。
PKCS #12定义了通常用来存储Private Keys和Public Key Certificates(例如前面提到的X.509)的文件格式,使用基于密码的对称密钥进行保护。注意上述Private Keys和Public Key Certificates是复数形式,这意味着PKCS #12文件实际上是一个Keystore,PKCS #12文件可以被用做Java Key Store(JKS),详见RFC7292。
openssl pkcs12 -export \
-in <cert> \
-inkey <private-key> \
-name my-cert \
-caname my-ca-root \
-CAfile <ca-cert> \
-chain
-out <pkcs-file>
PKCS #12一般不导出PEM编码格式。
当你不知道你的PEM文件内容是什么格式的可以根据下面查询。
RFC7468 - Textual Encoding of Certificates
-----BEGIN CERTIFICATE-----
BASE64Encoded
-----END CERTIFICATE-----
RFC7468 - Textual Encoding of Subject Public Key Info
-----BEGIN PUBLIC KEY-----
BASE64Encoded
-----END PUBLIC KEY-----
没有RFC或权威Specification,该格式有时候被称为traditional format、SSLeay format(见SO)
-----BEGIN RSA PRIVATE KEY-----
BASE64Encoded
-----END RSA PRIVATE KEY-----
同上没有RFC或权威Specification
-----BEGIN RSA PUBLIC KEY-----
BASE64Encoded
-----END RSA PUBLIC KEY-----
RFC7468 - One Asymmetric Key and the Textual Encoding of PKCS #8 Private Key Info
-----BEGIN PRIVATE KEY-----
BASE64Encoded
-----END PRIVATE KEY-----
RFC7468 - Textual Encoding of PKCS #8 Encrypted Private Key Info
-----BEGIN ENCRYPTED PRIVATE KEY-----
BASE64Encoded
-----END ENCRYPTED PRIVATE KEY-----
生成PKCS #1格式的RSA Private Key
openssl genrsa -out private-key.p1.pem 2048PKCS #1 -> Unencrypted PKCS #8
openssl pkcs8 -topk8 -in private-key.p1.pem -out private-key.p8.pem -nocryptPKCS #1 -> Encrypted PKCS #8
openssl pkcs8 -topk8 -in private-key.p1.pem -out private-key.p8.pem过程中会让你输入密码,你至少得输入4位,所以PKCS #8相比PKCS #1更安全。
PKCS #8 -> PKCS #1
openssl rsa -in private-key.p8.pem -out private-key.p1.pem如果这个PKCS #8是加密的,那么你得输入密码。
PKCS #8 Unencrypted -> PKCS #8 Encrypted
openssl pkcs8 -topk8 -in private-key.p8.nocrypt.pem -out private-key.p8.crypt.pem过程中会让你输入密码,你至少得输入4位。
PKCS #8 Encrypted -> PKCS #8 Unencrypted
openssl pkcs8 -topk8 -in private-key.p8.crypt.pem -out private-key.p8.nocrypt.pem -nocrypt过程中会要求你输入Private Key密码。
提取指的是从Private Key中提取Public Key,openssl rsa同时支持PKCS #1和PKCS #8的RSA Private Key,唯一的区别是如果PKCS #8是加密的,会要求你输入密码。
提取X.509格式RSA Public Key
openssl rsa -in private-key.pem -pubout -out public-key.x509.pem提取PKCS #1格式RSA Public Key
openssl rsa -in private-key.pem -out public-key.p1.pem -RSAPublicKey_outopenssl x509 -in cert.pem -pubkey -noout > public-key.x509.pemX.509 RSA Public Key -> PKCS #1 RSA Public Key
openssl rsa -pubin -in public-key.x509.pem -RSAPublicKey_out -out public-key.p1.pemPKCS #1 RSA Public Key -> X.509 RSA Public Key
openssl rsa -RSAPublicKey_in -in public-key.p1.pem -pubout -out public-key.x509.pem先将自动更新之类的取消掉。
执行下面两条命令:
defaults write com.apple.systempreferences AttentionPrefBundleIDs 0
Killall Dock
就完成了。
<form class="layui-form" method="">
<input type="hidden" name="venue_info_id" value="1">
<div class="layui-row" style="padding-top: 40px">
<div class="layui-form-item text-right">
<button class="layui-btn" type="button" lay-filter="doCreateEvent" lay-submit>
<i class="layui-icon"></i>提交保存
</button>
</div>
</div>
</form>
form.on('submit(doCreateEvent)', function(data){
layer.confirm('确定添加预约?', {
skin: 'layui-layer-admin',
shade: .1
}, function (i) {
layer.close(i);
var loadIndex = layer.load(2);
$.post("/api/xxx", data.field, function (res) {
layer.close(loadIndex);
if (200 === res.code) {
layer.msg(res.msg, {icon: 1});
setTimeout(function (){
parent.location.reload();
}, 2500)
} else {
layer.msg(res.msg, {icon: 2});
}
});
});
});
{field: 'start_time', title: '生效时间', templet: function(d) {
return util.toDateString(d.start_time * 1000, 'yyyy-MM-dd HH:mm:ss')
}},
admin.open({
success: function(mData) {
//时间选择器
laydate.render({
elem: '#start_time',
type: 'datetime',
value: mData ? new Date(mData.start_time * 1000) : '',
});
}
});

内核:在一些系统中,当系统调用发生时,操作系统或者操作系统内核会编程应用程序内存的一部分。
栈:栈中包含活动记录,其中包含当前活动函数调用的返回地址和局部变量等信息。
共享库:为了动态链接共享库文件而创建的一个内存片段
堆内存:被用作堆内存来使用和分配的一块内存空间。如果运行时需要一些可变大小的小内存块,那么这些内存就是从这个区域中分配的
未初始化的数据: 没有初始化的全局变量被放在固定地址中。通常,这段区域都会被初始化为0。
初始化的数据: 任何被赋予了初始值的数据都被组织在内存中的一段连续的区域内,因此他们就能够与程序页一同被有效地载入
程序页:构成应用程序的机器代码指令就是程序页。当有硬件支持时,程序页通常是只读的,这样就可以防止程序意外的重写其自身指令区域。
第0页:通常,一个以地址0为开始的内存片段会被保留下来被设置为不可读区域,他可以用来捕捉一种常见的错误,这种错误就是使用一个NULL指针访问数据。
1 内存地址是从高地址到低地址进行分配的:
int i=1;
int j=1;
cout
2 函数参数列表的存放方式是,先对最右边的形参分配地址,后对最左边的形参分配地址。
3 Little-endian模式的CPU对操作数的存放方式是从低字节到高字节的
0x1234的存放方式入下:
0X4000 0x34
0X4001 0x12
4 Big-endian模式的CPU对操作数的存放方式是从高字节到低字节的
0x1234的存放方式入下:
0x4000 0x12
0x4001 0x34
5 联合体union的存放顺序是所有成员都从低地址开始存放。
6 一个变量的地址是由它所占内存空间中的最低位地址表示的。
0X4000 0x34
0X4001 0x12
0x1234 的地址位0x4000
7 堆栈的分配方式是从高内存地址向低内存地址分配的。
int ivar=0;
int iarray[2]={11, 22};
注意iarray[2]越界使用,比如对其赋值
iarray[2]=0;
那么则同时对ivar赋值为0,可能产生死循环,因为它们的地址相同,即&ivar等于&iarray[2]。
一 在C中分为这几个存储区
1.栈 由编译器自动分配释放;
2.堆 一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收;
3.全局区(静态区),全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。 程序结束释放;
4.另外还有一个专门放常量的地方。 程序结束释放。
在函数体中定义的变量通常是在栈上,用malloc, calloc, realloc等分配内存的函数分配得到的就是在堆上。在所有函数体外定义的是全局量,加了static修饰符后不管在哪里都存放在全局区(静态区),在所有函数体外定义的static变量表示在该文件中有效,不能extern到别的文件用,在函数体内定义的static表示只在该函数体内有效。另外,函数中的”adgfdf”这样的字符串存放在常量区。比如:
int a = 0; //全局初始化区
char *p1; //全局未初始化区
void main()
{
int b; //栈
char s[] = "abc"; //栈
char *p2; //栈
char *p3 = "123456"; //123456{post.content}在常量区,p3在栈上
static int c = 0; //全局(静态)初始化区
p1 = (char *)malloc(10); //分配得来得10字节的区域在堆区
p2 = (char *)malloc(20); //分配得来得20字节的区域在堆区
strcpy(p1, "123456");
//123456{post.content}放在常量区,编译器可能会将它与p3所指向的"123456"优化成一块
}
他们分别是堆、栈、自由存储区、全局/静态存储区和常量存储区
在bbs上,堆与栈的区分问题,似乎是一个永恒的话题。
首先,我们举一个例子:
void f()
{
int* p=new int[5];
}
这条短短的一句话就包含了堆与栈,看到new,我们首先就应该想到,我们分配了一块堆内存,那么指针p呢?它分配的是一块栈内存,所以这句话的意思就是:在栈内存中存放了一个指向一块堆内存的指针p。
在程序会先确定在堆中分配内存的大小,然后调用operator new分配内存,然后返回这块内存的首地址,放入栈中,他在VC6下的汇编代码如下:
00401028 push 14h
0040102A call operator new (00401060)
0040102F add esp,4
00401032 mov dword ptr [ebp-8],eax 这里写代码片
00401035 mov eax,dword ptr [ebp-8]
00401038 mov dword ptr [ebp-4],eax
这里,我们为了简单并没有释放内存,那么该怎么去释放呢?是delete p么?错了,应该是delete []p,这是为了告诉编译器:我删除的是一个数组,VC6就会根据相应的Cookie信息去进行释放内存的工作。
好了,我们回到我们的主题:堆和栈究竟有什么区别?
主要的区别由以下几点:
1、管理方式不同;
2、空间大小不同;
3、能否产生碎片不同;
4、生长方向不同;
5、分配方式不同;
6、分配效率不同;
管理方式:对于栈来讲,是由编译器自动管理,无需我们手工控制;对于堆来说,释放工作由程序员控制,容易产生memory leak。
空间大小:一般来讲在32位系统下,堆内存可以达到4G的空间,从这个角度来看堆内存几乎是没有什么限制的。但是对于栈来讲,一般都是有一定的空间大小的,例如,在VC6下面,默认的栈空间大小是1M(好像是,记不清楚了)。当然,我们可以修改:
打开工程,依次操作菜单如下:Project->Setting->Link,在Category 中选中Output,然后在Reserve中设定堆栈的最大值和commit。
注意:Reserve最小值为4Byte;commit是保留在虚拟内存的页文件里面,它设置的较大会使栈开辟较大的值,可能增加内存的开销和启动时间。
碎片问题:对于堆来讲,频繁的new/delete势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。对于栈来讲,则不会存在这个问题,因为栈是先进后出的队列,他们是如此的一一对应,以至于永远都不可能有一个内存块从栈中间弹出,在它弹出之前,在它上面的后进的栈内容已经被弹出,详细的可以参考数据结构,这里我们就不再一一讨论了。
生长方向:对于堆来讲,生长方向是向上的,也就是向着内存地址增加的方向;对于栈来讲,它的生长方向是向下的,是向着内存地址减小的方向增长。
分配方式:堆都是动态分配的,没有静态分配的堆。栈有2种分配方式:静态分配和动态分配。静态分配是编译器完成的,比如局部变量的分配。动态分配由alloca函数进行分配,但是栈的动态分配和堆是不同的,它的动态分配是由编译器进行释放,不需要我们手工实现。
分配效率:栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高(我的注释:关于EBP寄存器请参考另一篇文章)。
堆则是C/C++函数库提供的,它的机制是很复杂的,例如为了分配一块内存,库函数会按照一定的算法
(具体的算法可以参考数据结构/操作系统)在堆内存中搜索可用的足够大小的空间,如果没有足够大小的空间
(可能是由于内存碎片太多),就有可能调用系统功能去增加程序数据段的内存空间,这样就有机会分到足够大小的内存,
然后进行返回。显然,堆的效率比栈要低得多。
从这里我们可以看到,堆和栈相比,由于大量new/delete的使用,容易造成大量的内存碎片;由于没有专门的系统支持,效率很低;由于可能引发用户态和核心态的切换,内存的申请,代价变得更加昂贵。所以栈在程序中是应用最广泛的,就算是函数的调用也利用栈去完成,函数调用过程中的参数,返回地址,EBP和局部变量都采用栈的方式存放。所以,我们推荐大家尽量用栈,而不是用堆。
虽然栈有如此众多的好处,但是由于和堆相比不是那么灵活,有时候分配大量的内存空间,还是用堆好一些。
无论是堆还是栈,都要防止越界现象的发生(除非你是故意使其越界),因为越界的结果要么是程序崩溃,要么是摧毁程序的堆、栈结构,产生意想不到的结果,就算是在你的程序运行过程中,没有发生上面的问题,你还是要小心,说不定什么时候就崩掉,那时候debug可是相当困难的:)